
cloud computing team organization
프로젝트 보고서
1. Project Abstract
MSA(Microservices Architecture)를 기반으로 프론트엔드, 백엔드, 데이터베이스를 컨테이너로 격리하고, Kubernetes 기반의 오토스케일링(HPA) 및 무중단 배포(Rolling Update) 환경을 구축한 프로젝트임. 인프라 리드로서 Cloud-Native한 자가 치유(Self-healing) 환경과 L4 기반 네트워크 격리 설계에 집중하여 엔터프라이즈급 고가용성 클러스터를 실현함.
- Period: 2025.11 - 2025.12 (팀 프로젝트 / 인프라 리드)
- Tech Stack: Kubernetes, Docker, Python(FastAPI), React, MySQL, Redis
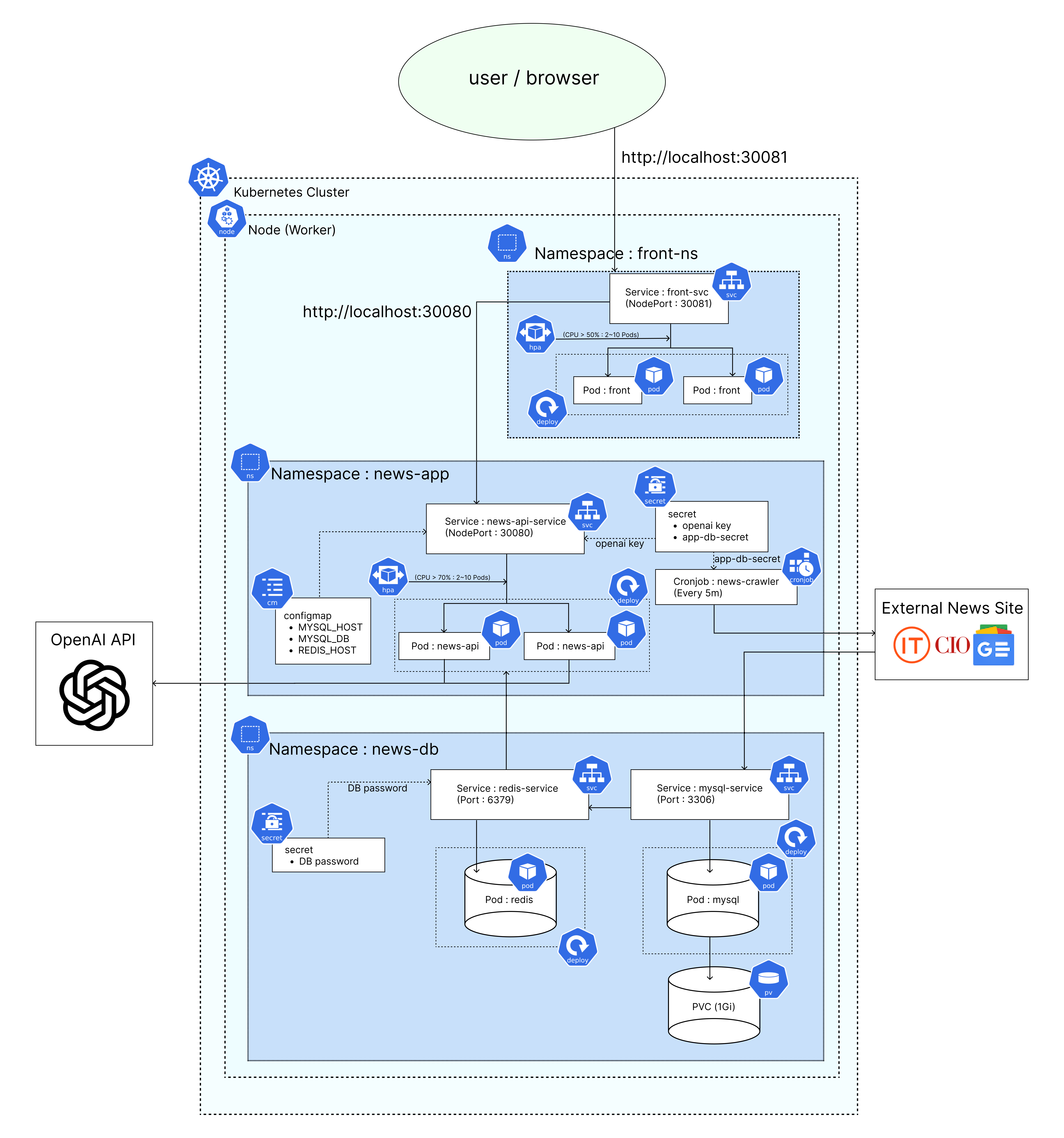
2. System Architecture: Cloud-Native & MSA 기반 설계
클러스터 전반에 걸쳐 리소스 최적화, 네트워크 보안, 데이터 영속성을 강화하여 트래픽 변동에 탄력적으로 대응하고 무중단 서비스를 보장하는 구조를 설계함.
A. 컨테이너 최적화 및 보안 전략
- Multi-stage Build
- 채택 근거: 빌드 아티팩트와 런타임 환경을 분리하여 이미지 경량화 및 공격 표면(Attack Surface) 최소화를 달성하기 위함임.
- 운영 방식:
Node.js빌드 스테이지에서 생성된 정적 자산만Nginx슬림 이미지로 이관함. 이를 통해 최종 이미지 크기를 기존 대비 70% 이상 절감하고 소스 코드 탈취 리스크를 원천 차단함.
- Base Image Optimization
- 메커니즘:
python:3.9-slim기반의 배포 이미지를 채택하여 런타임에 불필요한 바이너리를 제거함. - 보안 성과: 이미지 내 패키지 최소화를 통해 OS 레벨의 취약점(CVE) 노출 가능성을 낮추고, 가벼운 이미지 사이즈로 파드 스케줄링 및 배포 속도를 향상시킴.
- 메커니즘:
B. 안정적인 자율 운영 시스템 (Kubernetes Workloads)
- Self-Healing & Zero Downtime
- 운영 방식: Deployment의 Rolling Update 전략을 통해 서비스 가동률 99.9%를 지향함. 특히
Readiness/Liveness Probe의 정교한 설정을 통해 비정상 파드를 자동으로 격리하고 재시작하는 Self-healing 메커니즘을 완성함.
- 운영 방식: Deployment의 Rolling Update 전략을 통해 서비스 가동률 99.9%를 지향함. 특히
- Automated Data Pipeline & Persistence
- 메커니즘: CronJob 리소스를 활용하여 5분 간격의 뉴스 큐레이션 파이프라인을 자동화함.
- 데이터 정착: 데이터 유실 방지를 위해 PVC(Persistent Volume Claim)를 활용한 정적 볼륨 바인딩을 적용함. MySQL 파드 재시작 시에도 스토리지 라이프사이클을 독립적으로 유지하여 데이터 영속성(Persistence)을 확보함.
- Horizontal Pod Autoscaler (HPA) & Cost Optimization
- 채택 근거: 트래픽 급증 시의 가용성 확보와 유휴 시간대의 리소스 비용 절감을 동시에 달성하기 위한 탄력적 확장 전략임.
- 운영 방식: CPU 부하 70%를 임계치로 설정하여 파드 인스턴스를 최대 10개까지 가변적으로 관리함으로써 리소스 낭비를 최소화함.
3. Key Engineering Decisions
A. 계층별 네트워크 격리 및 보안 설계
- L4 레이어 네트워크 이원화
- 외부 노출 (NodePort): 사용자 접근이 필수적인 Web/API 서버는 전용 포트(30081, 30080)를 개방하여 트래픽을 수용함.
- 내부 보안 (ClusterIP): DB(MySQL)와 Cache(Redis)는 클러스터 내부 전용 IP로 구성함. 외부 접근을 원천 차단하고 FQDN(Full Domain Name) 통신을 통해 파드 IP 변경과 무관한 안정적인 연결성을 보장함.
- Secret & ConfigMap을 통한 설정 분리
- 메커니즘: OpenAI API Key, DB 패스워드 등 민감 정보는 K8s Secret으로 암호화 관리하고, 일반 설정값은 ConfigMap으로 분리함. 소스 코드 수정 없이 운영 환경을 전환할 수 있는 배포 멱등성을 확보함.
B. Polyglot Persistence 및 데이터 영속성
- PVC(Persistent Volume Claim) 기반 데이터 보존
- 운영 방식: 컨테이너의 휘발성 문제를 해결하기 위해 1Gi 용량의 PVC를 MySQL 파드에 마운트함. 파드 재시작 시에도 데이터 수명주기를 독립적으로 유지하여 영구 보존성을 확보함.
- MySQL + Redis 하이브리드 캐싱 전략
- 채택 근거: 빈번한 DB I/O 병목을 해소하고 메인 화면 로딩 속도를 개선하기 위함임.
- 운영 방식: Look-aside 캐싱 패턴을 적용하여 고빈도 뉴스 데이터를 Redis 메모리 상에서 서빙함. TTL(만료 시간) 관리로 메모리 효율을 높이고 API 응답 속도를 밀리초(ms) 단위로 단축함.
4. Technical Deep Dive (Problem Solving)
Issue: 트래픽 변동에 따른 탄력적 리소스 관리 (HPA 설계)
- Challenge: 특정 시점에 사용자 요청이 급증할 경우, 단일 Pod 체제에서는 CPU 부하로 인한 응답 지연 및 서비스 중단 위험이 존재함.
- Solution: Kubernetes의 **HPA(Horizontal Pod Autoscaler)**를 도입함. CPU 사용량이 임계치(70%)를 초과할 경우 실시간으로 부하를 감지하여 Pod 개수를 자동으로 확장(Scale-out)하도록 설계함.
- Result: 부하 테스트 결과, CPU 사용량 증가에 따라 Replicas가 2개에서 최대 7개까지 점진적으로 확장되어 안정적인 응답 속도를 유지함을 검증함.
Issue: 이기종 환경 간 이미지 빌드 호환성 및 Rolling Update 실패 개선
- Challenge: Windows 환경에서 빌드된 Docker 이미지가 Linux 기반 Kubernetes 클러스터 내에서 정상적으로 구동되지 않아 Rolling Update가 중단되는 현상 발생. 이는 실행 환경(OS 아키텍처) 차이로 인한 바이너리 호환성 문제로 확인됨.
- Solution: Docker의
Multi-platform build전략을 도입하거나 가상화된 빌드 환경을 통해 Linux 배포판에 최적화된 이미지 패키징을 수행하도록 수정함. - Result: 신규 이미지 배포 시 기존 Pod를 하나씩 종료하고 새 Pod를 생성하는 과정을 거쳐 Zero Downtime 배포를 성공적으로 안착시킴.
Issue: CronJob 기반 수집 파이프라인의 데이터 정합성 확보
- Challenge: 5분 간격의 주기적인 크롤링(CronJob) 수행 시, 이미 수집된 동일 기사가 중복 저장되어 DB 저장 공간 낭비 및 데이터 무결성 저해 이슈 발생.
- Solution (Code Level):
- DB 스키마 최적화: 뉴스 URL(link) 필드에
UNIQUE제약 조건을 추가하여 물리적인 중복 입력을 차단함 [코드 참조]. - Logic 개선: SQL의
INSERT IGNORE구문을 활용하여 수집된 데이터 중 중복된 링크는 자동으로 건너뛰고 새로운 기사만 적재하는 로직을 구현함 [코드 참조]. - 캐싱 레이어 활용: Redis를 통해 'daily_top3' 키로 최신 뉴스만 상시 업데이트(TTL 적용)하여 최전방 조회 성능을 개선함.
- DB 스키마 최적화: 뉴스 URL(link) 필드에
- Result: 크롤링 주기마다 발생하는 불필요한 트랜잭션을 최소화하고, 수집 성공 시 "중복 건너뜀" 메시지를 로그로 기록하여 파이프라인의 투명성을 확보함.