
1. Project Abstract
Kafka 기반의 Event-Driven Architecture를 적용하여 뉴스 데이터 수집(Producer)과 색인(Consumer) 프로세스를 분리(Decoupling)한 분산 처리 시스템입니다. Spring WebFlux와 Elasticsearch Async Client를 도입해 전 구간 Non-blocking I/O를 구현하였으며, 이를 통해 단일 인스턴스 내에서 동시 요청 처리량(Throughput)을 극대화하고 시스템의 내결함성(Fault Tolerance)을 확보했습니다.
- Period: 2025.08 - 2025.09 (1개월, 개인 프로젝트)
- Role: Backend Engineering & Infrastructure Architecture (100%)
- Tech Stack: Java 17, Python, Spring Boot (WebFlux), Apache Kafka, ELK Stack (Elasticsearch, Logstash, Kibana), Docker Compose
2. System Architecture
데이터 수집부터 조회까지 전 구간에 걸쳐 비동기/논블로킹 지향 설계를 적용함으로써, 시스템의 내결함성(Fault Tolerance) 과 확장성(Scalability) 을 동시에 확보한 점에 있음.
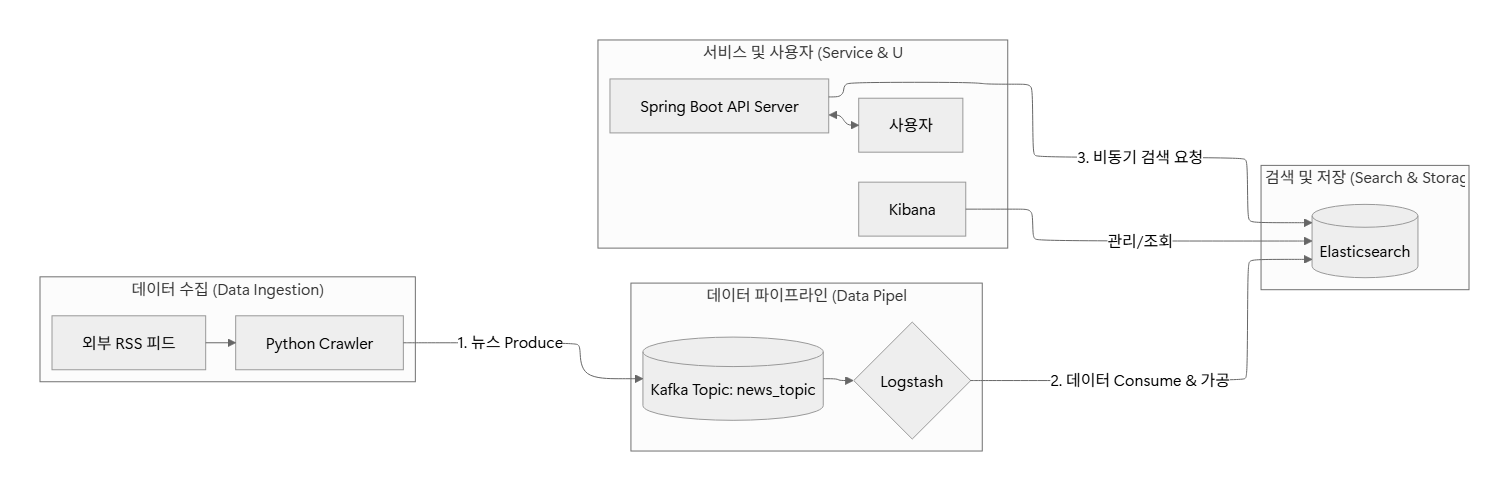
A. Data Ingestion & Streaming: Decoupling 중심
- Python Crawler & Kafka Producer
- 채택 근거: I/O Bound 작업인 웹 크롤링의 특성상, 파이썬의 비동기 라이브러리를 활용하여 수집 효율을 극대화함. 수집 직후 저장소에 직접 Write 하지 않고 Kafka를 거치는 이유는 **Producer-Consumer 간의 시공간적 결합도를 해소(Decoupling)**하기 위함임.
- 운영 방식: 뉴스 피드를 파싱한 Semi-structured 데이터를 JSON 직렬화하여 Kafka Topic(
news_topic)으로 발행함. 이 과정에서 Kafka는 **영속성(Durability)**을 보장하는 중간 버퍼 역할을 수행하며, 하위 시스템의 장애가 수집 단계로 전파되는 것을 차단함.
- Apache Kafka (Distributed Message Broker)
- 채택 근거: 서비스 규모 확장 시 발생하는 Backpressure(배압) 현상을 제어하기 위한 핵심 인프라임. 소비자(Logstash)의 처리 속도가 공급자(Crawler)를 따라가지 못할 때, 메시지를 디스크에 안전하게 큐잉하여 데이터 유실을 원천 봉쇄함.
- 운영 방식: 파티셔닝 전략을 통해 데이터 순서를 보장하거나, 필요시 컨슈머 그룹의 수평적 확장(Scale-out)을 유도하여 병렬 처리 성능을 가변적으로 조절함.
- Kafka Partitioning & Consumer Strategy
- 채택 근거: 서비스 규모 확장 시 발생하는 Backpressure(배압) 현상을 제어하고 병렬 처리 성능을 확보하기 위함임.
- 운영 방식:
news_topic에 3개의 파티션을 할당하고, Logstash의consumer_threads설정을 파티션 수와 1:1로 매칭하여 처리량(Throughput)을 극대화함. - 메커니즘: Python Crawler(Producer)에서 뉴스 URL을 해싱하여 고유 ID를 생성함. 이를 통해 기사 중복 수집을 방지하는 동시에 파티션 간 데이터를 균등하게 분배(Round-robin 효과)함.
- 예외 처리:
auto_offset_reset => "latest"설정을 적용하여, 컨슈머 재시작 시점의 최신 데이터부터 처리함으로써 실시간 뉴스 수집의 정시성을 확보함.
B. Pipeline & Storage: 최적화된 인덱싱 전략
- Logstash (Data Pipeline)
- 채택 근거: 다수의 Input 원천으로부터 데이터를 수집하고, 검색 엔진에 최적화된 형태로 **ETL(Extract, Transform, Load)**을 수행하기 위해 도입함.
- 운영 방식: Kafka Consumer로서 메시지를 Polling 한 후, 불필요한 메타데이터 제거 및 정형화(Grok filter 등)를 거쳐 Elasticsearch로 Push 함.
- Elasticsearch (Search Engine)
- 채택 근거: 대용량 비정형 텍스트 데이터에 대한 Full-text Search(전체 텍스트 검색) 성능을 확보하기 위함임. B-Tree 기반의 RDBMS와 달리 Inverted Index(역색인) 구조를 활용하여 질의 응답 시간을 O(1)에 가깝게 수렴시킴.
- 운영 방식: ILM(Index Lifecycle Management) 정책을 적용하여 데이터의 신선도에 따라 Hot/Warm 노드로 분산 배치함으로써 스토리지 비용과 검색 효율을 동시에 최적화함.
C. Application Architecture: Non-blocking 파이프라인
전 구간 비동기 파이프라인을 구축하여 I/O 대기 시간 동안 CPU 자원이 낭비되는 Thread Blocking 현상을 원천 제거함. 이를 통해 동시 요청이 급증하는 상황에서도 시스템 성능 저하를 최소화하고 높은 응답성을 유지함.
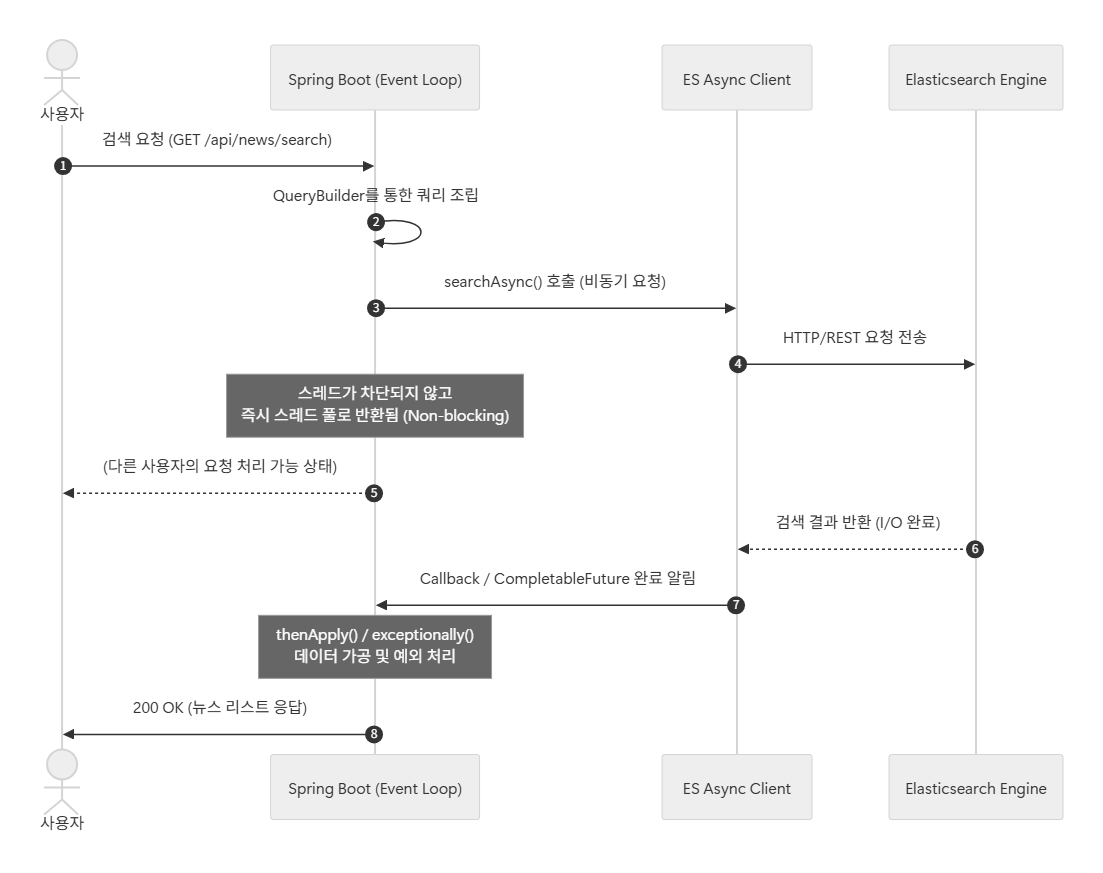
- Spring WebFlux & Async Client
- 채택 근거: 기존 Thread-per-request 모델(Spring MVC)의 한계인 Context Switching 오버헤드와 Thread Pool Exhaustion(스레드 풀 고갈) 문제를 해결하기 위함임.
- 운영 방식: Event Loop 기반의 Non-blocking I/O를 구현함. Elasticsearch와의 통신 대기 시간 동안 스레드 점유를 해제하고 자원을 반납하여, 최소한의 리소스로 극대화된 **동시성(Concurrency)**을 확보함.
- CompletableFuture & Exception Handling
- 메커니즘:
CompletableFuture체이닝을 통해 요청부터 색인 조회까지의 전 과정을 비동기로 설계함.searchNewsAsync호출 시 스레드는 응답을 대기하지 않고 즉시 스레드 풀로 반환되어 다른 HTTP 요청을 즉각 처리함. - 예외 처리: 비동기 호출 연쇄 과정에서 발생하는 예외를
exceptionally또는handle메서드로 캡슐화함. 검색 엔진 장애나 타임아웃 발생 시에도 시스템 전체로 장애가 전파되는 Cascading Failure를 방지하고, Fallback 데이터를 제공하는 **Graceful Degradation(단계적 기능 저하)**을 실현함.
- 메커니즘:
D. Infrastructure: IaC 및 모니터링
- Docker Compose (Container Orchestration)
- 채택 근거: 분산 시스템 구성 요소들의 의존성 관리 및 배포 환경의 **멱등성(Idempotency)**을 보장하기 위함임. 개발 환경과 운영 환경의 간극(Mirroring)을 최소화함.
- Kibana
- 운영 방식: 인덱싱 상태 모니터링 및 검색 쿼리 프로파일링을 수행하며, 시각화 대시보드를 통해 데이터 수집 추이를 실시간 관제함.
3. Key Engineering Architecture
A. Decoupling Logic with Kafka (결합도 해소 및 내결함성 확보)
- Background: 기존 모놀리식 구조의 크롤러는 DB 부하 발생 시 수집 로직 전체가 중단되는 강한 결합도(Tight Coupling) 문제를 보유.
- Implementation: Apache Kafka를 Message Broker로 도입하여
Python Crawler(Producer)와Logstash/Elasticsearch(Consumer)를 물리적으로 분리. - Result:
- Backpressure Handling: 색인 속도가 수집 속도를 따라가지 못할 때 Kafka가 버퍼 역할을 수행하여 데이터 유실 방지.
- Scalability: 데이터 유입량 급증 시 Consumer Group 단위의 수평적 확장(Scale-out)이 가능한 유연한 아키텍처 구축.
B. Non-blocking I/O Implementation (스레드 효율성 극대화)
- Background: 대량의 검색 트래픽 발생 시 Blocking I/O(Spring MVC) 방식은 Thread Pool Exhaustion으로 인한 Latency 증가 우려.
- Implementation:
- Spring WebFlux 도입 및 Elasticsearch Async Client 활용.
- 검색 요청(
searchAsync) 후 I/O 대기 시간 동안 스레드가 다른 작업을 처리하도록CompletableFuture기반의 비동기 파이프라인 설계.
- Result: 제한된 컴퓨팅 리소스 환경에서도 Context Switching 비용을 최소화하며 높은 동시성(Concurrency) 처리 성능 달성.
C. Infrastructure as Code & Automation (운영 효율화)
- Docker Compose: Zookeeper, Kafka, ELK, Application 등 6개 컨테이너의 복잡한 의존성을 코드로 정의(IaC)하여 배포 멱등성 보장.
- ILM (Index Lifecycle Management): 시계열 데이터 특성을 반영, Hot-Warm-Delete 정책을 템플릿화하여 스토리지 운영 비용 최적화 및 샤드 관리 자동화.
4. Technical Deep Dive (Problem Solving)
Issue: 검색 정밀도와 성능 간의 Trade-off 최적화
- Challenge: 단순 텍스트 매칭(
match) 쿼리만으로는 정확도 낮은 결과가 반환되고, 불필요한 스코어링(Scoring) 연산으로 쿼리 속도가 저하되는 현상 확인. - Solution: Bool Query 구조 재설계 (Compound Query)
- Must Clause: 정확도가 필수적인 키워드 매칭에 적용하여 Relevance Score 산출.
- Filter Clause: 날짜 범위(
range) 등 단순 필터링 조건에 적용. Elasticsearch 내부의 Filter Cache를 적극 활용하여 스코어링 연산을 생략, 검색 속도를 획기적으로 개선. - Hybrid Logic: 검색어/기간 유무에 따라 동적으로 쿼리를 조립하는
QueryBuilder로직을 구현하여 다양한 검색 패턴에 대응.
Issue: 비동기 데이터 흐름의 예외 처리
- Challenge: 외부 API(Elasticsearch) 호출 실패 시, 비동기 체인이 끊기거나 에러 전파가 불명확한 문제.
- Solution:
CompletableFuture의exceptionally처리를 통해, 검색 엔진 타임아웃이나 연결 실패 시에도 Fallback 데이터를 반환하거나 커스텀 에러로 래핑하여 클라이언트에 안정적인 응답(Graceful Degradation)을 보장하도록 설계.
Issue: 대용량 데이터 전처리 및 인덱싱 효율 최적화
- 메커니즘 (ETL 및 데이터 정제):
- 수집 단계(Python): BeautifulSoup을 활용한 HTML 태그 제거 및
is_clickbait필터링 로직을 수집 엔진에 직접 구현함. 불필요한 데이터를 원천 차단하여 스토리지 낭비와 불필요한 인덱싱 연산을 방지함. - 가공 단계(Logstash):
date플러그인을 통해 RSS 피드별 상이한 날짜 포맷(ISO8601, UNIX 등)을 Asia/Seoul 타임존으로 표준화하여 시계열 분석의 데이터 정합성을 확보함.
- 수집 단계(Python): BeautifulSoup을 활용한 HTML 태그 제거 및
- 채택 근거 (Elasticsearch 쿼리 최적화):
- 구조 설계:
Bool Query구성 시 검색어는must클로즈에, 날짜 범위는filter클로즈에 배치하는 이분화 전략을 사용함. - 운영 방식: 정확도가 필요한 키워드 매칭에만 스코어링을 적용하고, 날짜 필터링에는 Elasticsearch Filter Cache를 강제로 활성화함. 이를 통해 반복적인 기간 조회 요청에 대한 CPU 연산 비용을 절감하고 검색 응답 속도를 획기적으로 개선함.
- 구조 설계: