

1. 이론
-
정의
Full-Text Index(FTI)는 텍스트 데이터를 빠르게 검색할 수 있도록 특화된 인덱스입니다.
일반 B-Tree 인덱스는 정확한 값 검색에 적합하지만, 문장/단어 검색, 부분 일치, 자연어 검색에는 비효율적입니다. -
주요 기능
자연어 검색 단어 단위, 형태소 단위 검색 가능 Boolean 검색 AND, OR, NOT 조건 검색 가능 부분 일치 검색 LIKE '%keyword%'보다 빠름 랭킹 단어 빈도/중요도 기반 결과 정렬 가능 -
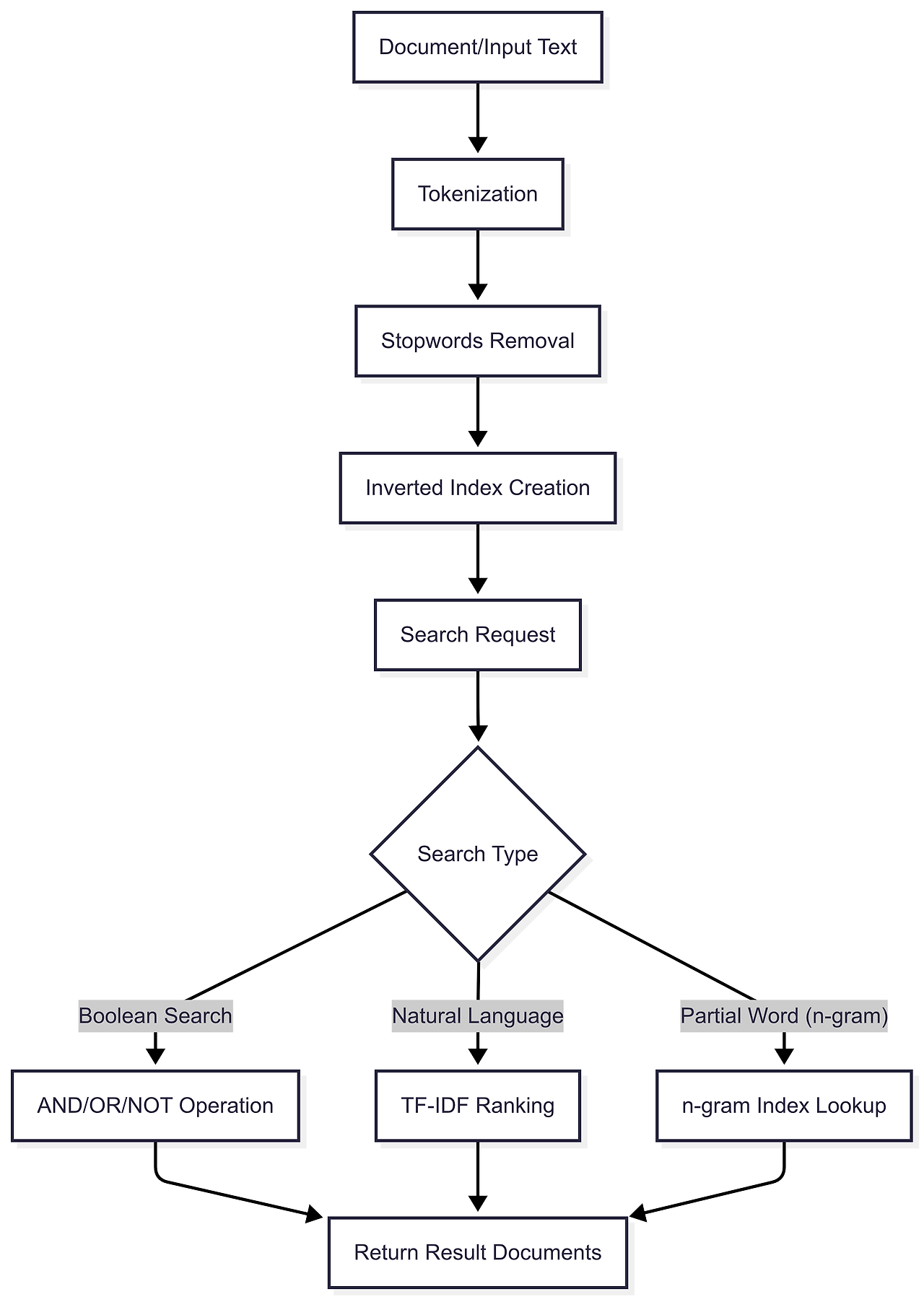
원리
- 텍스트를 토큰화(Tokenization)
- 역색인(Inverted Index) 생성
- 단어 → 등장 문서 목록
- 검색 시 단어별 문서 집합 교집합/합집합 연산 → 결과 반환
2. 활용
- RDBMS 예제 (MySQL)
-- Full-Text Index 생성
CREATE FULLTEXT INDEX idx_content ON posts(content);
-- Full-Text 검색
SELECT * FROM posts
WHERE MATCH(content) AGAINST('Java Spring' IN NATURAL LANGUAGE MODE);
-- Boolean 검색
SELECT * FROM posts
WHERE MATCH(content) AGAINST('+Java -Python' IN BOOLEAN MODE);
- Elasticsearch 예제
GET /posts/_search
{
"query": {
"match": {
"content": "Java Spring"
}
}
}
- 활용 사례
- 블로그 검색
- 상품 검색
- 문서 검색 시스템
- 질문/답변 검색 (QA 서비스)
3. 심화
-
검색 모드
Natural Language 일반 문장 검색, 랭킹 기반 결과 Boolean AND/OR/NOT, 포함/제외 조건 지정 가능 Query Expansion 유사어, 동의어 기반 확장 검색 -
성능 최적화
- 자주 검색되는 단어는 stopwords로 제외
- n-gram, edge n-gram 활용 → 부분 단어 검색 가능
- 캐싱 + 페이징 처리 → 대용량 데이터 최적화
-
RDBMS vs 전문 검색엔진
구축 난이도 낮음 높음 검색 속도 중 ~ 대량 느림 빠름 복잡한 검색 Boolean 수준 자연어, 형태소, 유사어, 랭킹 확장성 제한적 분산 처리 가능
4. 면접 대비 핵심 포인트
- Full-Text Index 원리: 토큰화 + 역색인
- RDBMS Full-Text vs 일반 인덱스 차이
- 검색 모드와 Boolean 검색 활용법
- 대규모 검색 성능 최적화 전략
- 전문 검색엔진 활용 시 장점과 단점
5. 면접 연습
Q1. 일반 인덱스와 Full-Text Index 차이?
A: 일반 인덱스 → 정확한 값 검색에 적합, 부분 일치나 자연어 검색 비효율. Full-Text Index → 단어 단위 토큰화 + 역색인으로 빠른 텍스트 검색 가능.
Q2. Boolean 검색이란?
A: AND(+), OR, NOT(-) 등 논리 연산자를 이용해 검색 조건을 지정하는 방식. 포함/제외 단어 검색 가능.
Q3. LIKE '%keyword%'와 Full-Text Index 차이?
A: LIKE → 모든 행 스캔 → 느림 Full-Text Index → 역색인 사용 → 검색 속도 빠름, 대규모 데이터 최적화 가능
Q4. 검색 성능 최적화 방법은?
A: Stopwords 제거, n-gram 활용, 캐싱, 페이징, 전문 검색엔진 사용 등
Q5. RDBMS Full-Text vs Elasticsearch 장단점?
A: RDBMS → 구축 쉬움, 검색 복잡성 제한, 대용량 성능 낮음 Elasticsearch → 분산 처리, 자연어/형태소 검색 가능, 구축 복잡
6. 마무리
- Full-Text Index는 텍스트 기반 검색 최적화 핵심 도구
- 원리 이해 → 토큰화 + 역색인
- 활용 → RDBMS, Elasticsearch, QA, 블로그, 상품 검색
- 면접 → Full-Text Index 원리, Boolean 검색, 성능 최적화, RDBMS vs 검색엔진 비교 설명 필수